업무를 하다보면, raw data를 받아볼 때
엑셀이 소화할 수 있는 행의 수를 넘어 정상적으로 파일이 오픈되지 않을 때가 있다.
보통 raw data는 엑셀을 통해 확인하지 않고 간접적으로 내용을 요약해서 본다거나 곧바로 분석하곤 할텐데,
그럼에도 일일히 열어보고 살펴봐야되는 순간이 없는 것은 아니다.
이럴 때에, 혹은 그 외의 경우에, csv나 txt파일을 더 적은 행으로 구분하고자 할 때가 있다.
간단하게 분리하는 법!
split -l 분리하고자 하는 행 수 파일명.csv 파일명_
로 프롬프트(Mac에서 터미널)에 명령하면 파일명_aa, 파일명_ab...의 방식으로 분류가 된다.
예를들어, test.csv를 10만 행씩 잘라 분류하고싶다면,
파일이 있는 위치를 먼저 알려준 다음 명령을 날려준다.
1. 터미널 오픈

2. 파일의 위치 지정
cd /Users/darom/Desktop/daromtest

3. 행 분리
split -l 100000 test.csv test_
를 바로 아래에 입력하면 바로 분리가 시작된다.
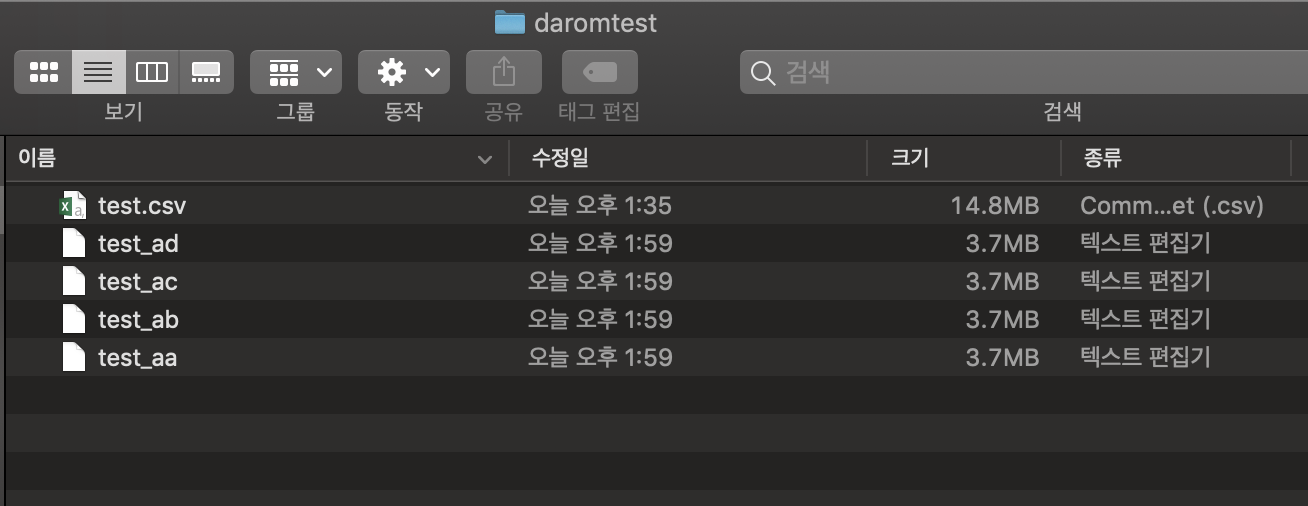
4. 합치기
반대로, "폴더 내에 있는 파일 다 하나로 합쳐줘!" 할 때
cat ./* > test.csv
를 입력하면 test.csv로 묶인다.
'분석하는 마케터' 카테고리의 다른 글
| Python - 아스키코드 문자 <-> 숫자 변환 (0) | 2019.11.04 |
|---|---|
| Python - 리스트 내포(List Comprehension) (0) | 2019.11.04 |
| Python - 형태소 분석(BeautifulSoup, konlpy) (0) | 2019.10.29 |
| 빅데이터 수집 적채 처리 실습 (0) | 2019.10.28 |
| Sublime text 줄바꿈/탭 공백 제거하기 (0) | 2019.04.03 |



댓글